

AI-enabled outcome stories – learning from partners to portfolio
ESLA Loopers – Robbie Gregorowski & Pedro Prieto Martin – July 2025
This ESLA Loops Better Practice Brief explains how the modest but productive application of AI can support partner ‘outcome story’ reporting, and then enable portfolio-level sense-making and adaptive learning processes. We share this example as a small contribution to the ongoing AI in MEL practice experimentation taking place across the field.
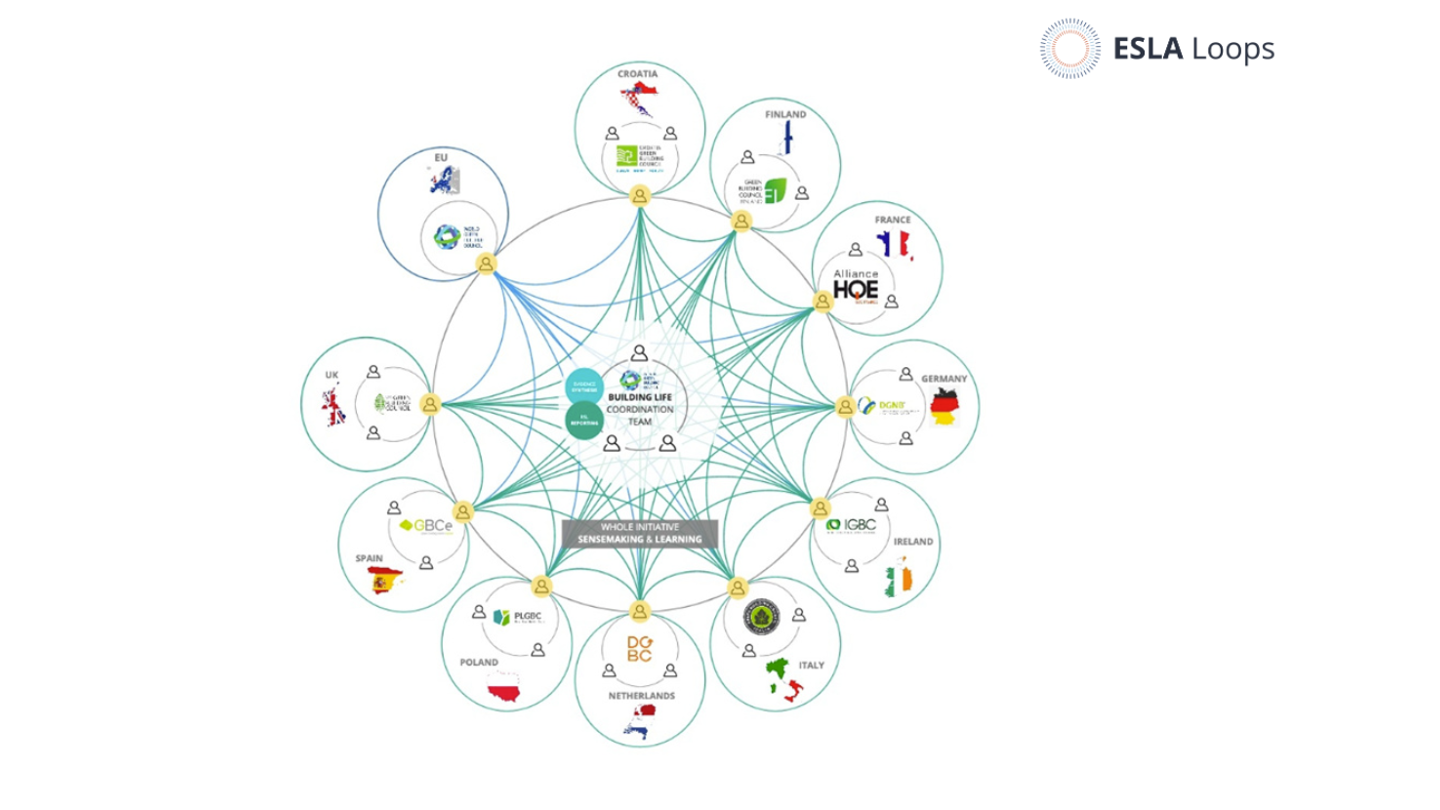
Recently we collaborated with the Impact Function at the Clean Air Fund to conduct a portfolio-level evaluation of their Low Cost Sensor initiative. A key feature of the evaluation was its focus on portfolio-level collaborative sense-making for adaptive learning, bringing together the Clean Air Fund team with 10 partners around the world. This allowed us to pilot the use of AI to gather insights from multiple grants and elaborate a consistent set of partner outcome stories, leveraging AI capacities to assist in systematic qualitative analysis and pattern recognition tasks and evaluations. [1, 2, 3] Instead of placing the story reporting ‘burden’ on partners as is commonplace, we offered to generate and synthesize the outcome-level evidence ourselves, enabling the partners to use their time to engage in more valuable and useful collaborative sense-making.
The evidence collection that we conducted with each partner combined our analysis of their routine results reporting data, plus any supporting documentation they wanted to provide, with one online semi-structured group interview using automatic transcription software.
This evidence was fed into dedicated NotebookLM projects, and synthesized through a set of queries and prompts. The syntheses were used initially to design and prepare for the interviews, and later to support the generation of a set of partner outcome stories, which followed a common template and structure – with 4 common sections: the underlying context; the outcome contribution; contextual enablers and constraints; and, future directions and course corrections. The collection of outcome stories allowed us to identify and examine patterns across the portfolio, and supported sense-making exercises conducted with the organization’s Impact Function and Data Portfolio Team.
We successfully deployed AI software to enhance productivity in two evaluative functions:
- The automated collection of group interview narrative data; and,
- The synthesis of multiple qualitative data sources (interviews, routine results reporting, and wider documentation) into a common narrative structure – outcome stories.
We see three key advantages of this practice:
- Helping partners who do not have the time or resources to report outcomes – The process demonstrates that it is both feasible and efficient for evaluators to generate rich, consistent, and informative evidence of individual partner and overall portfolio outcomes in contexts where this evidence does not already exist.
- Helping initiatives to generate consistent portfolio-level outcome evidence – As well as generating relatively robust and representative evidence of overall portfolio contributions, outcome stories can form the foundation for portfolio-level collaborative sense-making processes – bringing together partners with deep experience and insight to explore how change happens within and across an initiative, and the systems and contexts they engage in.
- Enabling partners to use their time for reflection and learning rather than data gathering and reporting – This way, the burden of generating and pre-analyzing these stories shifted from partners to evaluators, enabling partners to spend their time in more valuable collaborative sense-making processes.
We offer six practice insights for those who want to replicate or refine the process:
- Focus on productivity – Use AI software where it improves productivity rather than where it offers ‘the answer’. Be pragmatic, aim for good enough (as opposed to ‘perfect’) approaches that enhance the effectiveness and quality of your work.
- Combine AI tools – At the time we used OtterAI for data collection (group interview transcription) and NotebookLM for several rounds of evidence-synthesis (systematically applied to each of the documents – interview transcripts, progress/results reports, and supporting documentation).
- Test and refine the strategies, queries and prompts – Careful planning and design of the processes need to be complemented with iterative cycles of pragmatic testing and refinement at all levels, from prompting approaches to establishing pathways to leverage insights into enhanced sense-making.
- ‘Human’ quality assurance becomes even more important – Agency and oversight from the researchers/evaluators are essential. This involves the design of the general enquiry and processes for sense-making and evaluation, the incorporation of AI support in places where it offers most value, and a constant engagement in the review and validation of all outputs constructed with AI support.
- Prioritize transparency and ethical practice – Be upfront with partners and stakeholders about your use of AI tools from the project outset. Clearly communicate how AI enhances rather than replaces human analysis, ensure appropriate data privacy and security measures, and maintain the same rigorous evaluation standards you would apply to any analytical process.
- Engage or develop the required technical expertise – To design and deliver AI-enabled outcome stories requires new skills of evaluators. This expertise can be developed through practice and testing, or can be engaged through partnerships with AI experts.
Looking ahead: AI capabilities are rapidly evolving
It’s worth noting that the AI landscape for evaluation work is evolving at remarkable speed. Current AI systems have significant limitations – from restricted context windows, unreliable responses and cumbersome multi-tool workflows to high costs [1, 2]. However, our own experience supports Ethan Mollick’s aphorism that “today’s AI is the worst AI you will ever use” [4]: NotebookLM, the tool we used for synthesizing outcome stories, already offers a substantially larger context window than earlier AI systems and is available at no cost. This suggests that the technical and financial barriers we encounter today will likely diminish rapidly, making AI-assisted evaluation approaches more accessible and effective for organizations of all sizes [2].
For evaluation practitioners, this means that while it’s valuable to experiment with current tools, it’s equally important to develop the underlying skills and frameworks for working with AI systems — skills that will transfer and improve as the technology advances.
Our next ESLA Loops Practice Brief will provide more details on how collaborative sense-making processes can be supported by AI, through enhanced collection and synthesis of partners’ outcome stories. Below we present brief illustrations of key steps in generating a set of AI-enabled outcome stories.
1 – Design an outcome story template

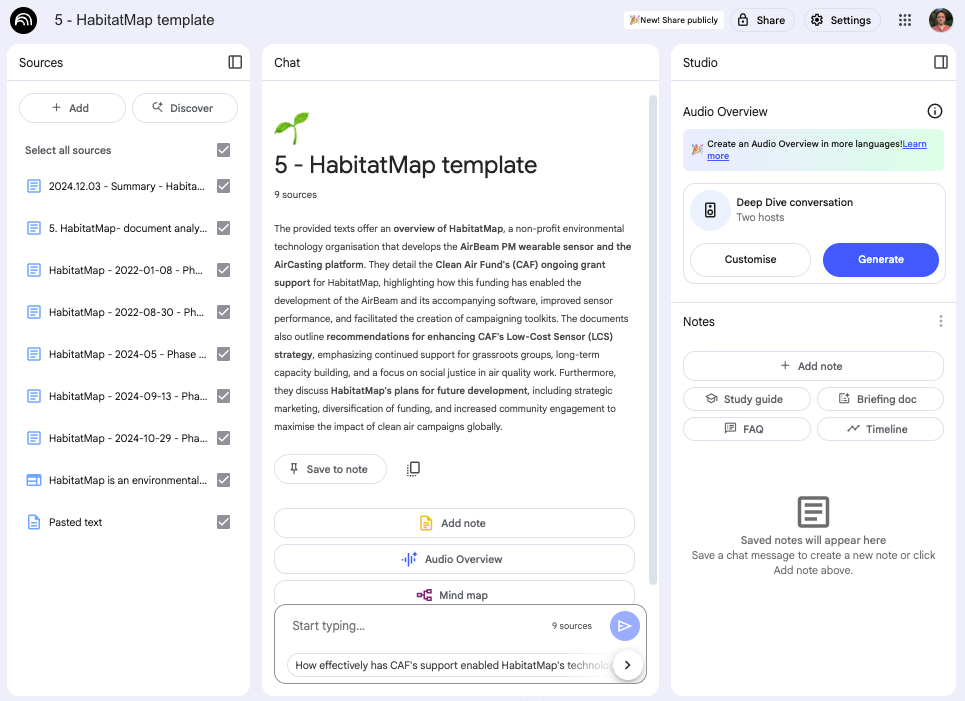
2 – Gather documents in NotebookLM’s workspaces, and query them using a set of standardised queries

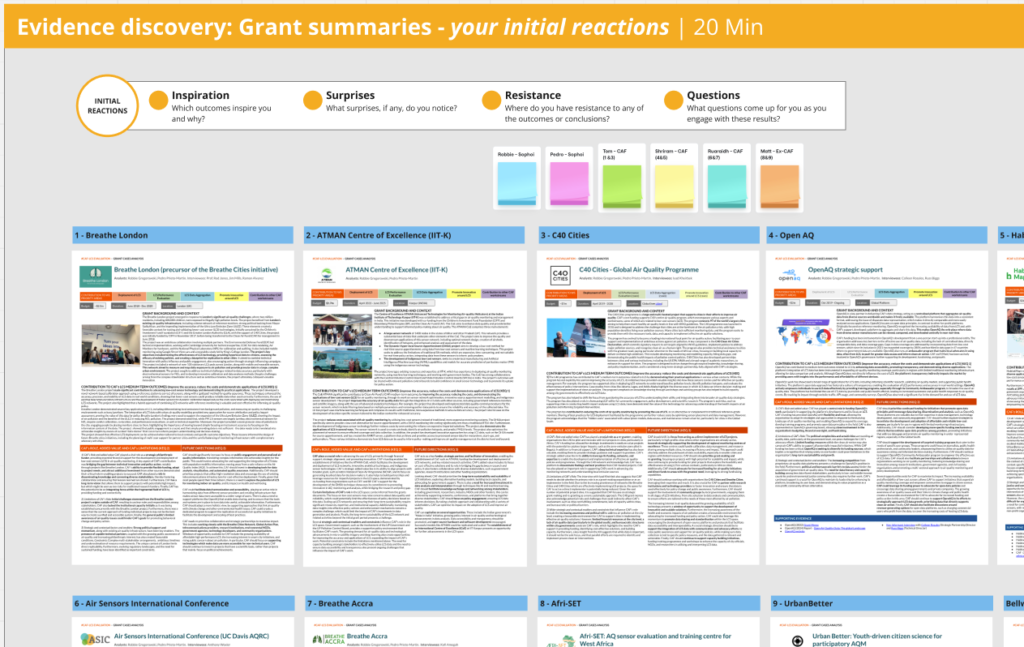
3 – Quality assure and curate a portfolio of outcome stories in Miro
References
[1] Nguyen-Trung, K. (2025) ‘ChatGPT in thematic analysis: Can AI become a research assistant in qualitative research?’, Quality & Quantity, http://doi.org/10.1007/s11135-025-02165-z
[2] Sabarre, N.R.; Beckmann, B.; Bhaskara, S. and Doll, K. (2023) ‘Using AI to disrupt business as usual in small evaluation firms’, New Directions for Evaluation 2023.178–179: 59–71, http://doi.org/10.1002/ev.20562
[3] Anuj, H.; Den Boer, H. and Raimondo, E. (2025) Balancing Innovation and Rigor: Guidance for the Thoughtful Integration of Artificial Intelligence for Evaluation, IEG-The World Bank & IOE-IFAD, https://documents1.worldbank.org/curated/en/099136005132515321/pdf/IDU-dccd6e52-4ee3-4294-a264-28fda8a94a49.pdf
[4] Mollick, E. (2024) Co-Intelligence: Living and Working with AI, London: Penguin Books Ltd.



