


Better Practice Brief 2
In the world of social impact and philanthropy, we face a persistent paradox. The challenges we address—like the climate emergency—are complex, dynamic, and unpredictable. Yet, the systems we use to understand impact are often rigid, extractive, and linear. Organizations struggle to bridge the gap between “reporting results” to funders and actually learning about how their portfolios contribute to systems change.
The solution isn’t to build a heavier, more complicated Monitoring, Evaluation, and Learning (MEL) architecture. The solution is to design a system that is relational, efficient, and deeply human. Grounded in the principles of ESLA Loops (Evidence, Sense-making, Learning, and Action), we can transform a “reporting burden” into a dynamic engine for strategic reflection and learning.
The Core Philosophy: ESLA Loops
Before diving into the steps, it is vital to understand the “operating system” behind this approach. ESLA Loops are based on the principle that those closest to the change process hold the deepest insights. The goal is to move from producing static “products” (like long reports no one reads) to facilitating “processes” where teams collaboratively make sense of evidence to inform action. At ESLA Loops, we have conducted a pilot where we successfully integrated three innovations into a coherent loop:
Conversation-Based Reporting (CBR) to generate rich, contextual evidence.
AI-Enhanced Analysis to synthesize complex data efficiently.
Collaborative Sense-Making to turn data into actionable strategy.
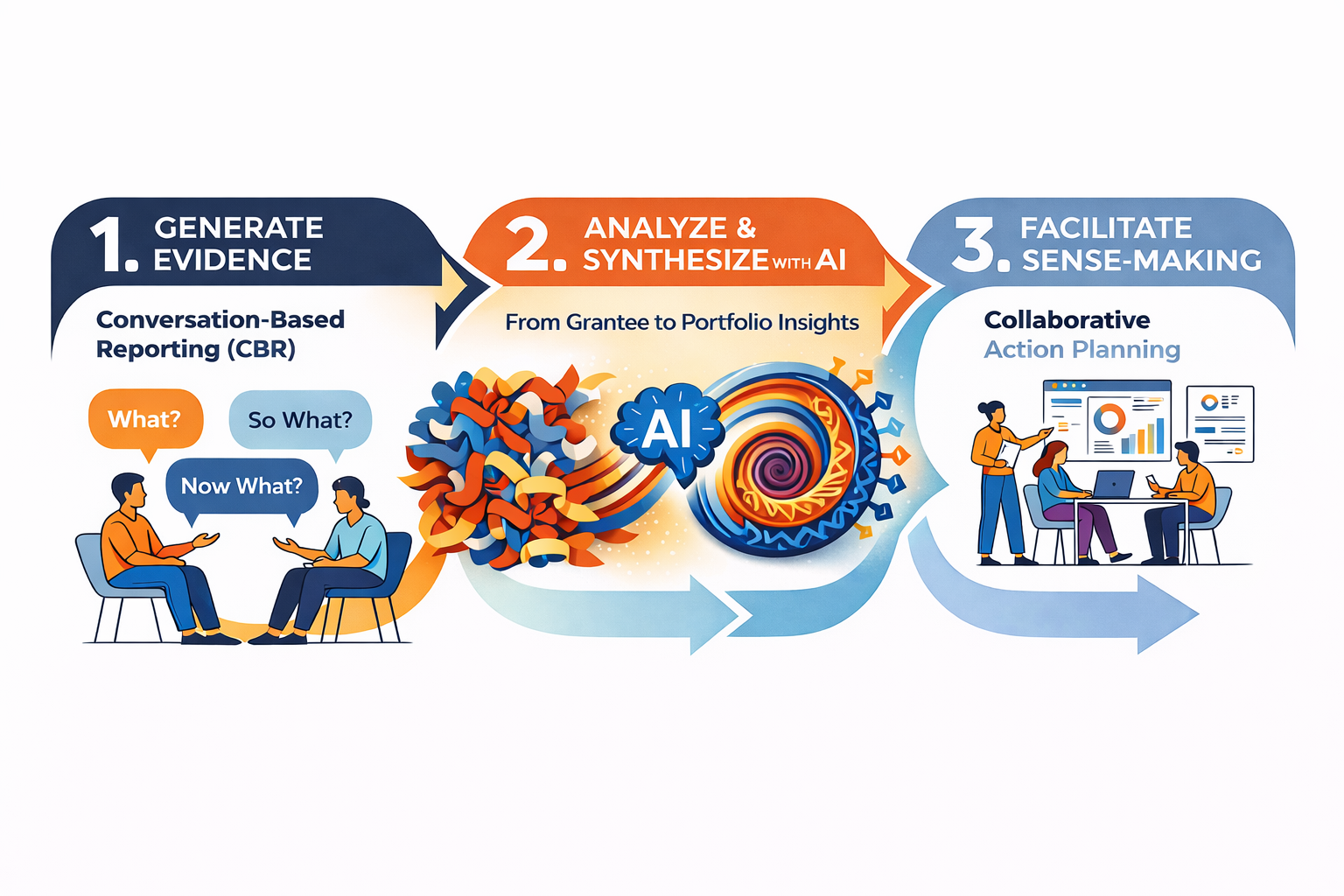
Here is how you can build this system in three practical steps.
Step 1: Generate Evidence through Conversation-Based Reporting
The first step requires a cultural shift from extraction to exchange. Traditional reporting often demands that grantees report against pre-determined KPIs that may no longer be relevant in a fast-changing context. This creates a “performance” rather than a true picture of impact.
The Innovation: Depth over Breadth – Instead of written narrative reports, the system uses an approach to Conversation-Based Reporting (CBR) developed by Laura Rana-Englert whilst she led the MEL function at the Climate Emergency Collaboration Group (CECG). These are semi-structured, story-based conversations between program officers and grantees. The focus shifts from checking boxes to exploring the “Most Significant Outcome” (MSO) and mapping contributions to the organization’s Theory of Change.
Practical Implementation:
- Shift the Medium: Replace written forms with recorded transcripts of 60-90 minute conversations.
- Ask the Right Questions: Use a “What? So What? Now What?” framework. Ask grantees to identify one significant real-world outcome, explaining why it matters and how the grant contributed alongside other actors.
- Map to Strategy: Use the conversation to map these outcomes to specific levers or drivers in your Theory of Change (e.g., “Implementation,” “Impacts,” “Integrity”).
Why it works: This approach generates “robust, representative, and useful evidence” of relative contribution and wider system signals. It turns reporting into a mutually beneficial reflective practice, where grantees feel heard, and funders gain deep, contextualized insights.
Step 2: Prepare Evidence using AI Analysis and Synthesis
The historic barrier to conversation-based reporting has been the sheer volume of qualitative data. Analyzing dozens of transcripts manually is time-prohibitive. This is where the second step—AI-Enhanced Data Analysis—becomes a game-changer.
The Innovation: NotebookLM as a Synthesis Engine – In the pilot, NotebookLM was used to analyze and synthesize grantee transcripts. Unlike open-ended generative AI, NotebookLM is “closed” reporting; it answers queries only based on the uploaded source material (the CBR transcripts), which boosts trustworthiness and reduces hallucinations.
Practical Implementation:
- Secure the Data: Ensure data security by using tools where uploaded documents are private and not used to train wider models.
- Iterative Prompting: Treat AI querying like a conversation. You cannot simply use a standard prompt once. You must refine your queries to generate evidence in formats that fit your sense-making needs.
- Create Structured Outputs: Use the AI to generate specific evidence assets for the portfolio.
- Grantee “Look-Up” Summaries: 400-word summaries of specific outcomes for individual grantees.
- Thematic Syntheses: Summaries of “Most Significant Outcomes” across the whole portfolio, or “Contextual Enablers and Barriers” presented as Mind Maps.
- Strategic Recommendations: Ask the AI to derive strategic and operational recommendations based on grantee feedback.
The Human-in-the-Loop: Crucially, AI does not replace the human. It accelerates the “drudgery” of summarization. A human expert must curate, review, and quality-assure the AI-generated content to ensure it captures the nuance of the portfolio. This step translates raw data into “evidence people can sense-make with”.
Step 3: Facilitate Collaborative Sense-Making for Action
Evidence alone does not lead to change. The third step is Collaborative Sense-Making. This is defined as “the capacity to make sense of the world so you can act in it”. This step moves the process from analysis to learning and strategy.
The Innovation: The Virtual Sense-Making Platform – Using a virtual whiteboard tool (like Miro), you create a visual environment where teams engage with the AI-synthesized evidence. The design should facilitate a journey through three cognitive stages: What? So What? and Now What?
Practical Implementation:
- Design the Platform: Create a workspace where evidence (from Step 2) is presented visually. Use specific frames for different distinct sessions, such as “Understanding Outcomes” or “Understanding Contextual Barriers”.
- Structure the Interaction: Do not just let people read. Use a facilitation rhythm.
- Individual Reflection: Participants read the evidence and add sticky notes (e.g., “What surprises you?”, “What resonates?”, “What is missing?”)
- Small Group Discussion: Diverse teams discuss patterns and tensions.
- Whole Group “Harvest”: Facilitators capture the collective insights on “What is important and why?”
- Focus on Action (The “Now What?”): The process must culminate in decision-making. Dedicate specific sessions to “Strategic Directions” and “15% Solutions”—steps that are within the team’s immediate power to implement.
Why it works: By subjecting evidence to scrutiny in groups, experiences are shared, biases are challenged, and actions become collectively owned. This transforms the team from passive consumers of reports into active architects of strategy.
Conclusion: From “Having to” to “Wanting to”
This 3-step system—CBR -> AI Synthesis -> Collaborative Sense-Making—offers a radical departure from traditional MEL. It is a shift from “products to processes,” valuing the quality of the engagement as much as the final report.
By implementing this system, organizations can achieve a profound cultural shift: moving from having to sense-make (for compliance) to wanting to sense-make (for strategy).
What does this mean?
- For grantees: It reduces the reporting burden and encourages honest reflection.
- For MEL teams: It utilizes AI to remove the heavy lifting of data processing, allowing them to focus on high-value strategic reflection and learning.
- For the organization: It creates a “complexity-aware” system that creates structural capacity for adaptive learning.
The result is not just a report. It is a portfolio-level understanding of how change happens, grounded in the reality of those doing the work, enabling practical adaptive learning.
If you are interested to hear more about innovative best practice in evidence – sense-making – learning please get in touch with Robbie Gregorowski – robbie@sophoi.co.uk



This is a very interesting and important piece.